Search Results:
Big transfer
posted on 21 Jul 2020 under category paper_review
Big Transfer (BiT): General Visual Representation Learning
Authors: Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby
- 위 내용은 논문 및 Yannic의 유튜브 리뷰를 참고하여 작성한 리뷰임
동기
CV 관련 SOTA를 살펴 보던 중 하나 골라서 살펴보게 되었다. 많은 경우에 내가 사용하는 딥러닝은 모델을 가져와서 fine-tuning 하는 방향으로 학습을 하게 될탠데, 잘 학습되어 있는 ResNet을 fine-tuning 하여 2020.07.21 기준 CIFAR-100, Flowers-102 데이터에서 정확도 1위를 하고 있는 논문에 대해서 살펴보려고 한다.
내용
앞서 서술한대로 CV에서의 전이 학습에 대한 논문이다. 모든 딥러닝이 그렇듯 CV또한 많은 데이터를 요하고 그동안의 문제에서는 다행이도 많은 데이터를 보유하고 있었다. 하지만 몇몇 분야의 경우 아직 큰 데이터를 보유하고 있지 않기 때문에 이 경우에 fine-tuning과정을 통해서 모델을 전이학습 하게 된다.
큰 데이터
이 논문에서 말하는 것은 그렇다면 정말로 큰 이미지 데이터셋을 학습한 pre-trained 모델을 갖고 시작하는 것이 더 좋지 않겠냐고 말하고 있다. 데이터와 인프라를 보유하고 있어야 할탠데 해당 논문은 Google Research에서 작성한 논문이다.
먼저 논문은 BiT(Big Transfaer)라고 하는 세가지 큰 데이터에셋에 대해서 학습을 진행 하였다. 가장 큰 BiT-L 모델은 JFT-300M 데이터 셋인 3억개의 이미지를 훈련하고, 두번째로 BiT-M 모델은 ImageNet-21k데이터 셋을 사용하여 총 1400만개의 데이터로 훈련하였다. 마지막으로 BiT-S 의 경우 130만개의 데이터로 학습 하였다.
아래 그림의 BiT-L의 전이학습 성능을 보면 성능이 매우 좋은것을 확인 할 수 있다. X축은 fine-tuning에서 사용된 레이블당 사용되는 이미지의 개수를 나타내는데 정말 적은 데이터로도 Baseline 이상의 성능을 보이는 것을 확인 할 수 있다.
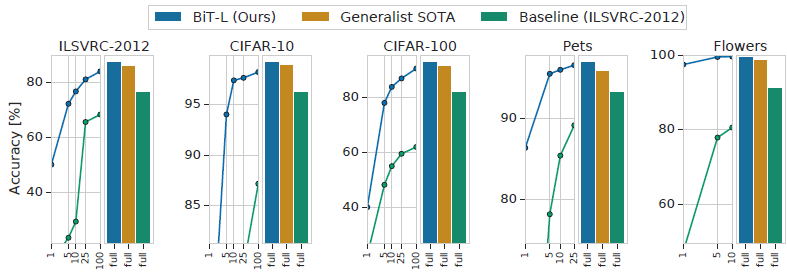
사전 훈련 및 전이학습 방법
사전훈련 방법
논문에서 전이학습시 좋은 성능을 낼 수 있는 pre-train방법에 대해서 두가지를 언급한다. 그중 첫번째로는 아래의 두가지가 필요하다고 말한다.
-
많은 양의 데이터
-
큰 모델
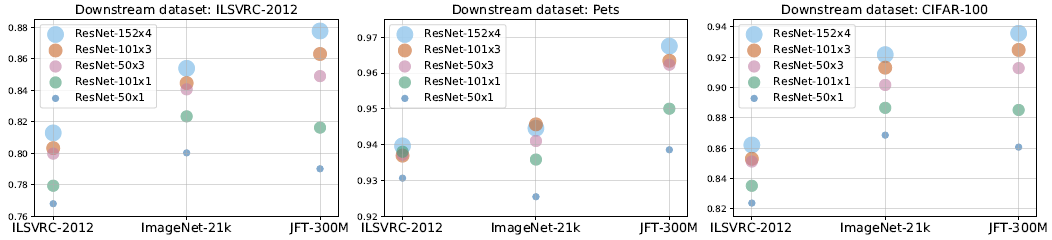
위의 그림을 보면 X축은 오른쪽으로 갈수록 큰 데이터 셋이고 원의 경우 클 수록 큰 모델이다. 일반적으로 큰 모델일 수록 더 나은 성능을 보이고 많은 양의 데이터에서 더 좋은 성능을 보이는 것을 확인 할 수 있다. 선형적으로 증가하는것은 아니고 오히려 작은 모델의 경우 큰 데이터가 더 안좋은 성능을 보이기도 하지만 데이터셋의 크기에 맞는 모델사이즈를 찾아야 하는점은 이견이 없을것이라고 생각한다.
Idea : 데이터에 맞는 최적의 모델 사이즈에 대한 연구
두번째 사전 좋은 사전훈련의 요소는 아래의 두가지 이다.
-
그룹 정규화(GN:Group Normalization)
-
가중치 표준화(WS:Weight Standardization)
기존의 대부분의 모델은 배치정규화(BN:Batch Normalization)를 사용하는 것을 볼 수 있었고 필자 또한 배치정규화의 도입으로 Dropout 없이도 오버피팅을 막는 것을 많이 목격하였기에 거의 필수라고 생각을 하였었다. 하지만 본논문에서는 BN이 큰 전이학습(BiT)에는 적합하지 않다고 주장하면서 두가지 이유를 말하는데 첫째로는 큰 모델에서 작은 배치사이즈로 학습 할 때(모델이 크기 때문에 GPU에 작은 배치를 넣을 수 밖에 없음) 동기화 비용(synchronization cost)이 너무 많이 든다는 것과 둘째로는 코드 실행중에 정규화를 위한 통계량을 계속 업데이트 해야 하기 때문에 전이학습에 BN은 좋은 방법이 아니라고 주장한다. GN의 경우에 동기화 비용은 존재하지 않지만 배치크기에 Scaleable하지 않을 수 있는데 이를 WS를 통해서 해결하였고, GN과 WS의 결합은 BN보다 더 뛰어낭 성능을 보여주었다.
전이학습 방법
Fine-tuning의 핵심은 사전학습에서 엄청난 수의 데이터와 큰 모델로 학습을 하였으니 이제는 쉽고 가볍게 전이학습을 하자는 것에 있다. 이 논문에서는 전이학습을 할 새로운 작업과 데이터 사이즈에 대해 값비싼 하이퍼 파라미터의 검색을 피하는것을 말하고 있다.
본 논문에서는 하이퍼파라미터 선택 방법으로 BiT-HyperRule을 제안하였다.
실험
실험결과는 아래와 같다. 여러 작업에 대해 SOTA를 넘는 성능을 보이는 것을 확인 할 수 있다.
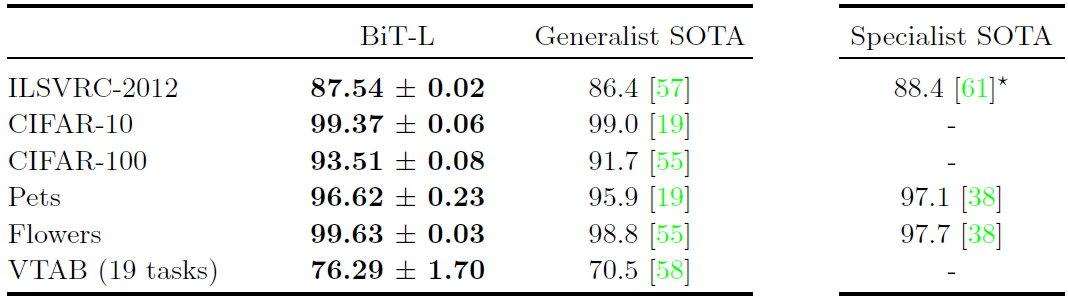
위의 결과 외에도 다양한 실험을 수행하였으며 모든 실험에서 (당연하겠지만) 좋은 성능을 보여준다.
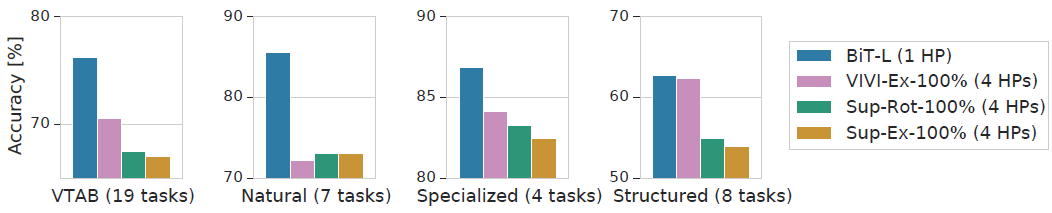
위의 실험 결과의 맨 오른쪽 결과에서 눈여겨 보아야할 점은 structured 작업에서는 기존의 성능에서 크게 벗어나지 않는 기존 작업과 유사한 성능을 보여준다는 점이다.
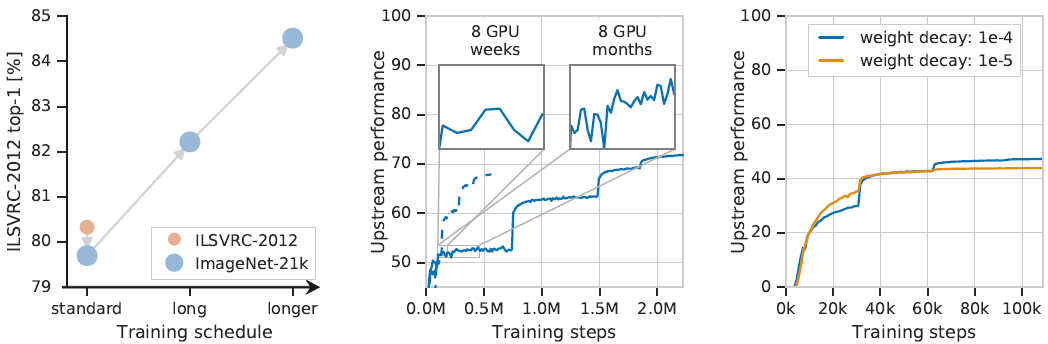
위의 실험 결과에는 사전학습에서 Learning Rate를 너무 일찍 낮추는 것은 좋은 방법이 아니라고 말한다. 기존에 모델을 더 큰 데이터에 적용할 때 충분히 오래 학습하는 것에 대해 말하는데 중간 결과에서 5십만 스텝과 2백만 스텝의 차이를 보여준다.
인사이트
자본주의 논문을 본 기분이었다. 큰 데이터, 큰 모델, 오랜 학습시간(OR 많은 GPU/TPU) 를 통해 팔방미인 모델을 제안하였다. 언어 모델에 GPT-3가 있었다면 비젼에서는 BiT모델이 있음을 알게 되었고 어느분야에 fine-tuning을 해서 이러한 모델을 내 문제에 가져올지 고민을 해봐야겠다.
많은 실무자들이 자신의 작업을 할 때 정말 좋은 출발점을 제안해주었다. 아이작 뉴턴 경이 ‘거인에 어깨위에 올라서 있었기 때문에 더 멀리 볼 수 있었다.’ 라고 하였는데 이 모델은 정말 큰 거인을 우리에게 제공해 주었다.